
No matter how unpredictable the world is, there is one thing you can count on: technology will continue to evolve. Everyone has heard of The Edge. But how do you get there?
Two decades ago, the introduction of Edge Computing changed the game, and installations started popping up in places far from traditional data spaces (under a cell tower, in a subway, on the factory floor, etc.)
We know we start in `The Cloud’. And we know The Edge is far removed from the enterprise data center; way, way out there – at the furthest limit of the network, right next to the processes, machines and sensors generating all that data. But is there something in between – something that provides an intermediate stop from The Cloud to The Edge?
Why You Haven’t Heard of the Spine
Edge computing efficiencies can be enhanced using a hub & spoke distribution model to enhance connections and efficiencies. It is a technique being used now, yet no one has established a proper name, nor defined what it actually is.
Some sources call this an “Edge Data Center,” but that confuses two different deployments. By definition, edge deployments are placed where data centers (large, secure buildings) can’t go and don’t belong. To use them together in one name muddles the waters instead of clarifying them.
“Spine” is Rittal’s way of explaining this functionality while rejecting misleading phrasing; and here's why it is appropriate.
Think of an airline. Its largest hub may be in Houston, yet there are many other hubs around the country: San Francisco, Los Angeles, Chicago, Denver, New York, and Washington DC. There is no single, main headquarters for all of its operations, yet they are all connected into a network. Now, look at the many small airports in remote locations as “Edge” locations. Between the big hubs and the remote locations are what Rittal would call the “spine” airports, the connectors that keep the network flowing in the hub & spoke plan (see “Innovative 3 Layer Topology” below).
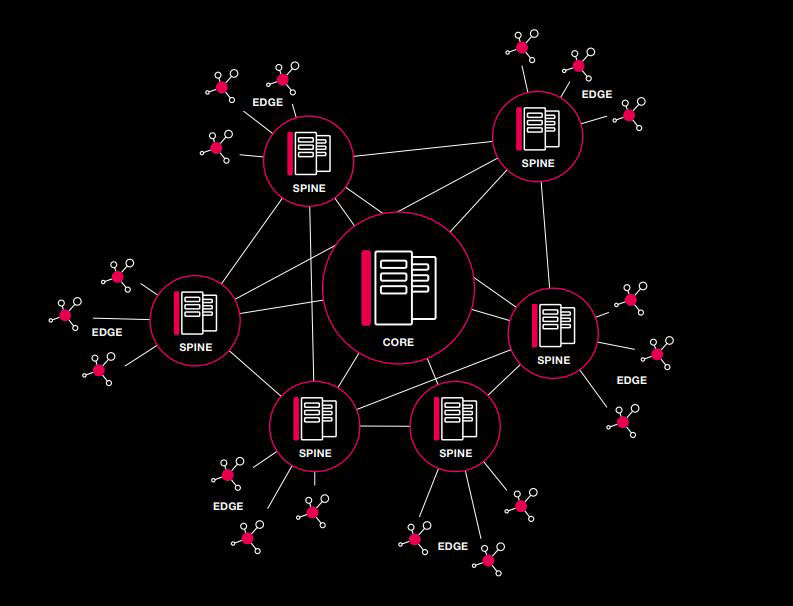
Innovative 3 Layer Topology - Edge, Spine, Core
In the graphic above, the “Edge” deployment is a standalone deployment: one or two footprints with climate control, power, security, cable management, etc. just like it is in the “Core” deployment. From hyper-local (“Edge”) to hyper-scale (large data centers, or “Core”), the biggest difference is the scale, not the contents.
The “Spine” also has the same contents, but it’s in the middle, receiving input and data from multiple Edge deployments and aggregating them. The spine contains network switches to filter and forward, and it also connects with other spines without having to go through the core.
Similarly (see below), the spine can act as a data center while connecting Edge deployments to the cloud.
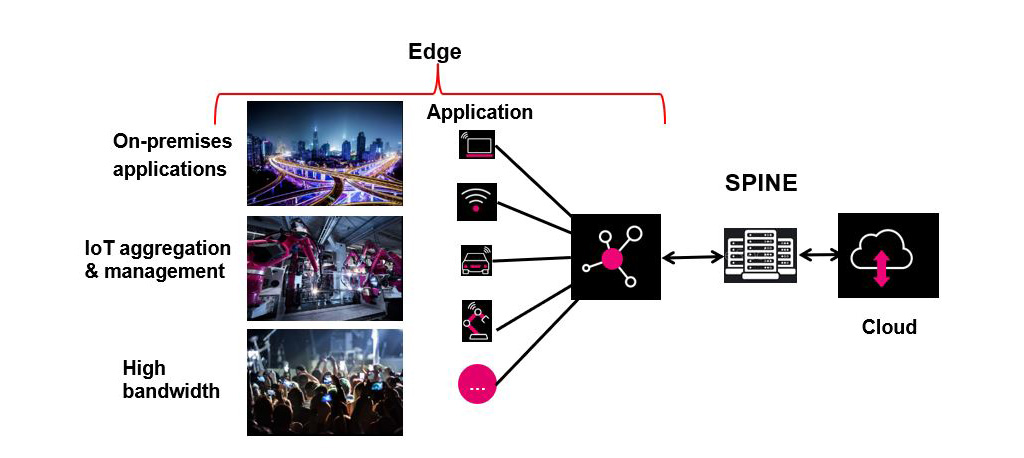
Edge Standalone Diagram
So, Where Are Spine Deployments Located?
Unlike an Edge deployment (as explained above: located anywhere BUT in a traditional data center), a Spine deployment can be located in a dedicated data center space, or it could be in a closet. Maybe a container located somewhere on the grounds of a factory, medical center or school campus. Obviously a 20-enclosure spine deployment won’t fit in an office closet down the hall, but one or two easily can. Three or four enclosures in an unused office – Sure. Ten in a repurposed classroom – Okay. It all depends on need and what is available.
How many footprints are in the typical spine deployment?
Instead of hundreds of enclosures in a large data center, the spine is
around 10-20 footprints (or whatever number is enough to handle
the Edge deployments it is assigned to support).
Are you using a spine deployment and not know it? Maybe you just haven’t called it “Spine.” If what you call an “Edge Data Center” is located in a traditional data center, it likely is not Edge. If it is located in a nontraditional environment (factory floor, etc.), it likely is Edge and could be “Spine” if it connects multiple Edge deployments.
The Why of the Spine
With “What is it?” and “Where is it?” answered, let us dive into “Why Spine exists?” Simply put, it provides local, higher levels of support for Edge applications, increasing process capabilities at the local level and interconnecting without having to go through the core.
A spine deployment expands efficiency in numerous ways:
- Improve Latency
- Increase Bandwidth
- Enhance Resiliency
- Increase Capabilities, Repeatability, Scalability
- Boost the Bottom Line
Understanding gained efficiencies, for instance, is as easy as thinking back to our airline analogy. Flying from New York to El Paso requires a changeover at the Houston hub. One stop isn’t nonstop, but it’s still a quick trip. If that route included flying from New York to Miami, then to Memphis, onto Houston, and then to El Paso, time triples, efficiency is gone, bandwidth is reduced, and resiliency is shot.
The hub-spoke distribution model comes alive when scaling from multiple Edge standalone platforms to a localized, concentration point in order to effectively process data.
Yes, spine adds a layer of IT management, which is critical to improving efficiency. Test this yourself. Google “Edge Computing” and see what pops up. Boom! Enjoy your 1,330,000,000 results in 0.62 seconds (no kidding; those are the real results.) That is the advantage of management at the software and application level. It does an incredible job at filtering, so the necessary results are shown in the most relevant order, according to Google, of course.
So moving forward, “Edge Data Center” doesn’t exist. The deployments that are called this — not in a traditional data center, yet large enough to hold a dozen footprints — are actually “spine” deployments, providing efficiency benefits across the network.
Ready to learn more about “Spine Edge” functionality? Talk to the experts at Rittal. You are also invited to watch our video, “Where Is the Edge?”


