
Modern data-heavy applications that use continuous analytics and are connected to high-performance machines require processing power as close as possible to where data is generated.
That need for proximity has resulted in Edge computing, processing data at the periphery — or “Edge” — of a network to handle mission-critical data in real-time. This proximity, at a hyper-local level, also reduces latency, reduces bandwidth (needed to send data to the cloud), minimizes storage costs, and improves overall network performance.
Driven by economics and efficiency, more and more companies are moving toward Edge computing, adding pressure to make Edge deployments as smooth and successful as possible from both the physical and application deployment. This article shares three critical tips that you should know.
Tip #1: Maximize Edge Computing’s Benefits
In Edge computing architecture, massive amounts of critical data generated and used in today’s IoT and Industry 4.0 environment is processed at the point of origin to optimize productivity. For example, when artificial intelligence’s immense data demands require fast performance, Edge computing’s infrastructure allows immediate action to be taken.
Productivity just scratches the surface of why you should care about Edge computing. The capabilities of Edge computing also provide complete control of processes and applications, alleviate the load on network resources, and reduce response time to milliseconds.
By processing data at the source, only the data required for transfer is shifted to a remote data center or cloud (see more in #2 below). The amount of data transmitted reduces the strain on bandwidth. By specifying criteria, data can be sorted to provide key analytics at the site and to push non-essential data to the center.
Edge computing is most valuable when massive data from smart devices would overload a data center. For instance, when monitoring the temperature of an IT cabinet, it is unnecessary to upload data in real time that is only valuable to the operations manager. If this data has historical value, it is pushed to a data center at a later time, or when bandwidth is not at a premium. This illustrates one of Edge computing’s major benefits.
The cloud and data centers are far from being obsolete, since long-term storage capacity is still needed.
Tip #2: Know What Edge is NOT
It is important to remember that an Edge deployment is not a data center, nor are Edge systems intended to eliminate reliance on the cloud. IT Managers should understand the difference between the Edge, cloud, and spine.
In a stand-alone Edge deployment, the most important data is processed immediately and locally, and the rest (not as time-sensitive or low priority) moves to the cloud for long-term storage. The cloud’s bandwidth was never meant to process huge amounts of data in real-time, but lower priority data can be sent to the cloud or to a remote data center.
Here is an example. An autonomous car has critical data needs that help the vehicle navigate properly and safely. The radar, sensors, scanners, etc. in a single autonomous vehicle generate 30 terabytes of data in one day. Edge alleviates that massive strain on bandwidth.
A `typical’ Enterprise data center is a fairly large facility, with hundreds of IT cabinets and the associated supporting infrastructure. An Edge deployment is at the hyper-local level - modular, and stand-alone deployment with one or two footprints. The real difference between the two is scale, not performance. These Edge deployments can be way out there, wherever machines and sensors are generating all that data. And depending on scale (number of Edge installations) and reach (how far from each one back to the core/enterprise space), an intermediate facility can be utilized. The Spine Data Center will support a `Hub and Spoke’ distribution model that improves connections and efficiency. After receiving and aggregating data from many Edge deployments, the spine uses network switches to filter and forward, connecting with other spines and the core.
INNOVATIVE 3 LAYER TOPOLOGY
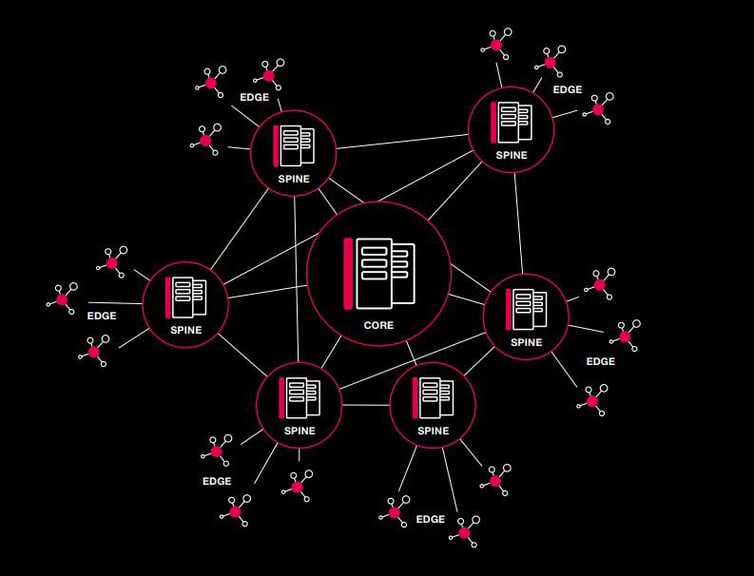
FROM EDGE... TO SPINE... TO CORE
Tip #3: Concentrate on Security
Although Edge deployments reduce latency and improve accessibility, security concerns and configuration architecture must be addressed. Because Edge stand-alone installations are isolated within a facility or “way out there,” there is likely no staff nearby, making reliable security — both physical and cyber — a concern.
Multiple components and communication channels — Edge computing’s distributed architecture — increase network vulnerabilities, with multiple vulnerable points for security breaches and infectious malware. With the configuration of the device, secure default passwords need to be placed on each device, and vigilance applied to the updating of software to avoid infiltration of malware.
Edge computing requires proactive IT management, with modern communication technology allowing for remote monitoring and reliable site management control. Video surveillance may be critical, monitoring activity around the equipment, and logs can track people accessing the space and the individual IT cabinets.
Some high-quality IT cabinets feature internal hinges, multi-point lock rods, and sturdy frame design. Prioritizing security helps deter break-ins, no matter where or what the Edge deployment is.
Rittal, a world leader in IT enclosure solutions, offers the CMC III system to monitor environmental conditions (water, smoke, heat, vandalism, power, access), control access, and collect numerous essential statistics from a centralized position. Customizable to be equipped with up to 32 sensors, the CMC III can also act independently, automatically initiating countermeasures and triggering alarms or notifying designated personnel.
Learn more about the Edge! Rittal’s handbook is loaded with helpful guidance on creating a successful Edge deployment. Click the link below to get your copy!
![Optimizing Edge Deployments [Pt. 1]: Real-World Computing Experiences](https://blog.rittal.us/hubfs/2021-Blog/Technician-monitoring-data.jpg)